Stream API
本文最后更新于:3 年前
引言
Java 8引入了StreamAPI,它标志着Java对函数式编程支持的一大步。Stream提供了一个高级抽象,使得集合操作更为简洁,同时提高了多核处理能力的利用。
概述
- 把真正的函数式编程风格引入到Java中,
java.util.stream包下 - 提供了一种高效且易于使用的处理数据(主要为集合类)的方式,可以进行处理集合,执行查找、过滤、映射数据等操作
Stream不改变源对象,会返回一个新的Stream- 代码书写干净、简洁、高效
操作步骤

创建Stream
一个数据源,如集合、数组,获取一个流
中间操作
一个中间操作过程,对数据源进行处理
终止操作
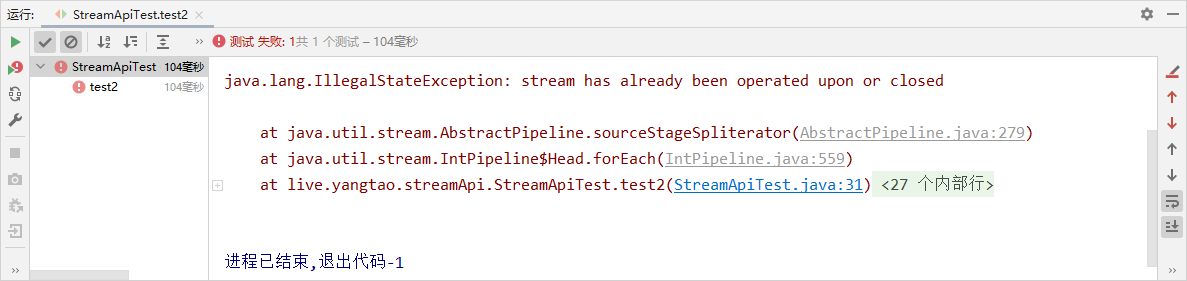
执行终止操作,就开始执行中间操作链,并产生结果,执行终止操作后,stream流不再可操作性,如:对同一stream流执行两次遍历
1
2
3
4
5
6public void test() {
int[] ints = new int[]{1, 2, 3};
IntStream stream = Arrays.stream(ints);
stream.forEach(System.out::println);
stream.forEach(System.out::println);
}
报错
Stream的创建
通过集合创建
通过数组创建
Stream.of(T… values)
并行流
无限流
1 | |
中间操作
中间操作可以拼接形成一个流水线
为方便测试,创建Person类和初始化列表List<Person>,详见文章底部附[1]
筛选与切片
Stream <T> filter(Predicate<? super T> predicate);过滤某些元素Stream <T> limit(long maxSize);限制长度Stream <T> skip(long n);跳过某些元素Stream <T> distinct();去重,通过hashCode和equals判定重复
1 | |
操作
Stream<T> peek(Consumer<? super T> action);对流中元素进行操作
1 | |
排序
Stream <T> sorted();默认的排序,自然排序Stream <T> sorted(Comparator<? super T> comparator);通过Comparator接口自定义排序规则
1 | |
映射
<R> Stream<R> map(Function<? super T, ? extends R> mapper);将流中每个值转换成另一个值并拼接成新的流<R> Stream <R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);将流中的每个值转换为另一个流,再把所有的流都拼接成一个流
1 | |
终止操作
匹配
boolean allMatch / anyMatch / noneMatch(Predicate<? super T> predicate);是否 全部 / 部分 / 不 匹配断言型函数定义的规则Optional\<T> findFirst();查找第一个元素Optional\<T> findAny();查找任意一个元素
1 | |
查找
long count();获取流中元素的个数Optional <T> max / min(Comparator<? super T> comparator);查找流中最大 / 小的元素,Comparator类型函数
1 | |
遍历
void forEach(Consumer<? super T> action);接收消费型函数,循环所有的元素
1 | |
规约
将流中的元素都结合起来,得到一个值,如计算总和
T reduce(T identity, BinaryOperator <T> accumulator);将所有的元素都结合起来得到一个值,并指定初始值Optional <T> reduce(BinaryOperator <T> accumulator);将所有的元素都结合起来得到一个值,无指定初始值<R> R reduce(R identity, BiFunction<R, ? super P_OUT, R> accumulator, BinaryOperator <R> combiner);并行流特有方法,并行流中的元素进行reduce操作,初始值为第1个参数,再将并行流的结果进行参数3的reduce操作
1 | |
收集
<R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner);使用收集器对此流的元素执行可变归约操作<R, A> R collect(Collector<? super T, A, R> collector);封装了用作collect(Supplier, BiConsumer, BiConsumer)参数的函数,允许重用收集策略和收集操作的组合,例如多级分组或分区
1 | |
Collectors的其他常见方法:
| 方法 | 返回类型 | 作用 |
|---|---|---|
| toList | List<T> | 收集为List |
| toSet | Set<T> | 收集为Set |
| toCollection | Collection<T> | 收集为创建的集合 |
| counting | Long | 计算流中元素的个数 |
| summingInt | Integer | 对流中元素的整数属性求和 |
| averagingInt | Double | 计算流中元素Integer属性的平均值 |
拓展
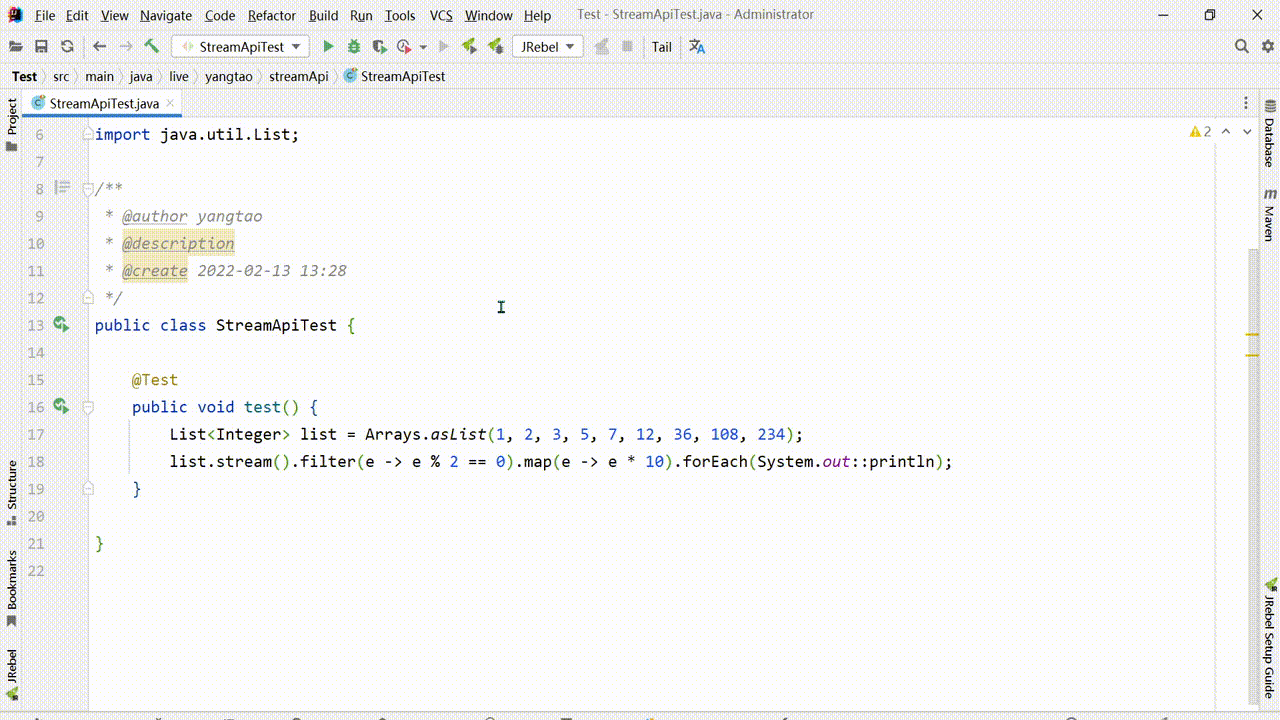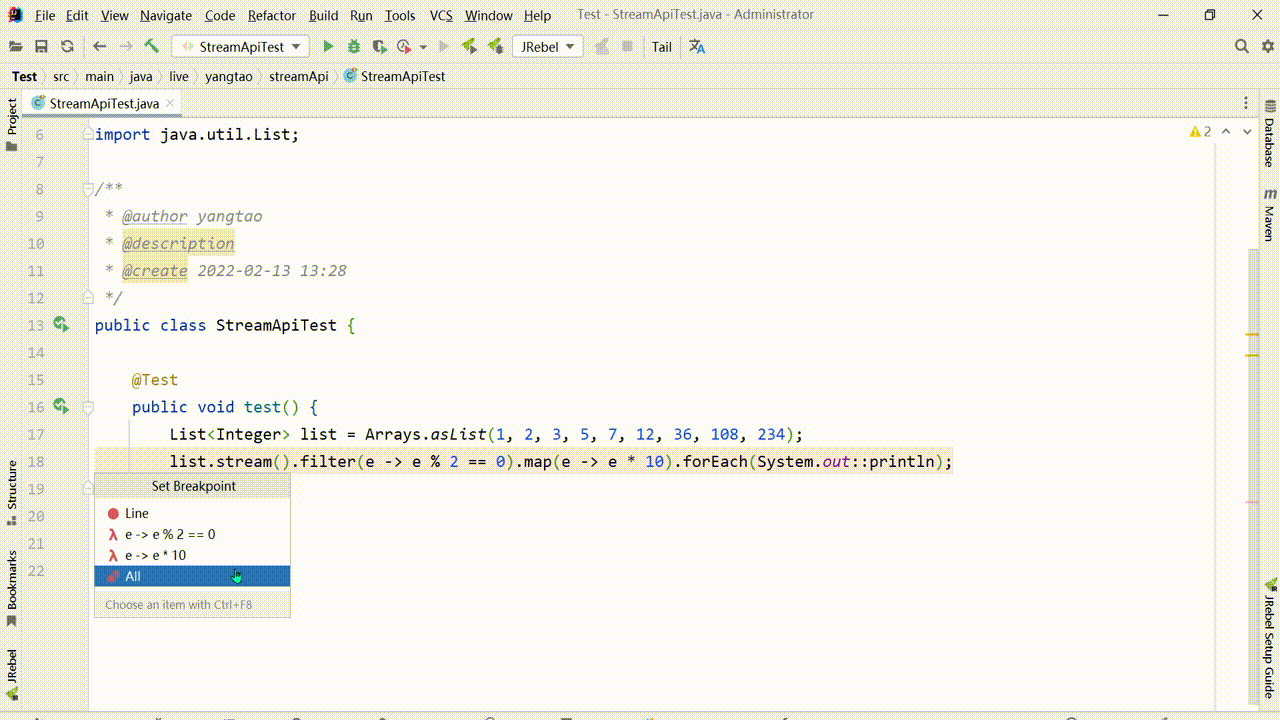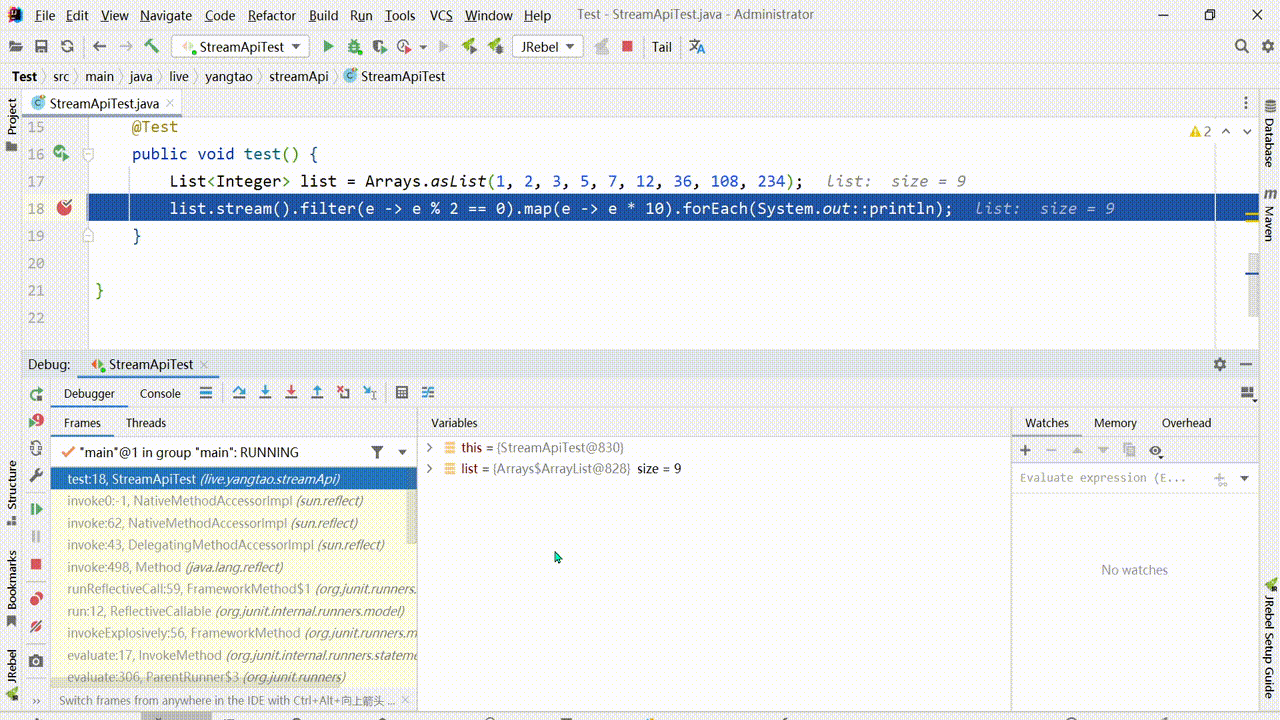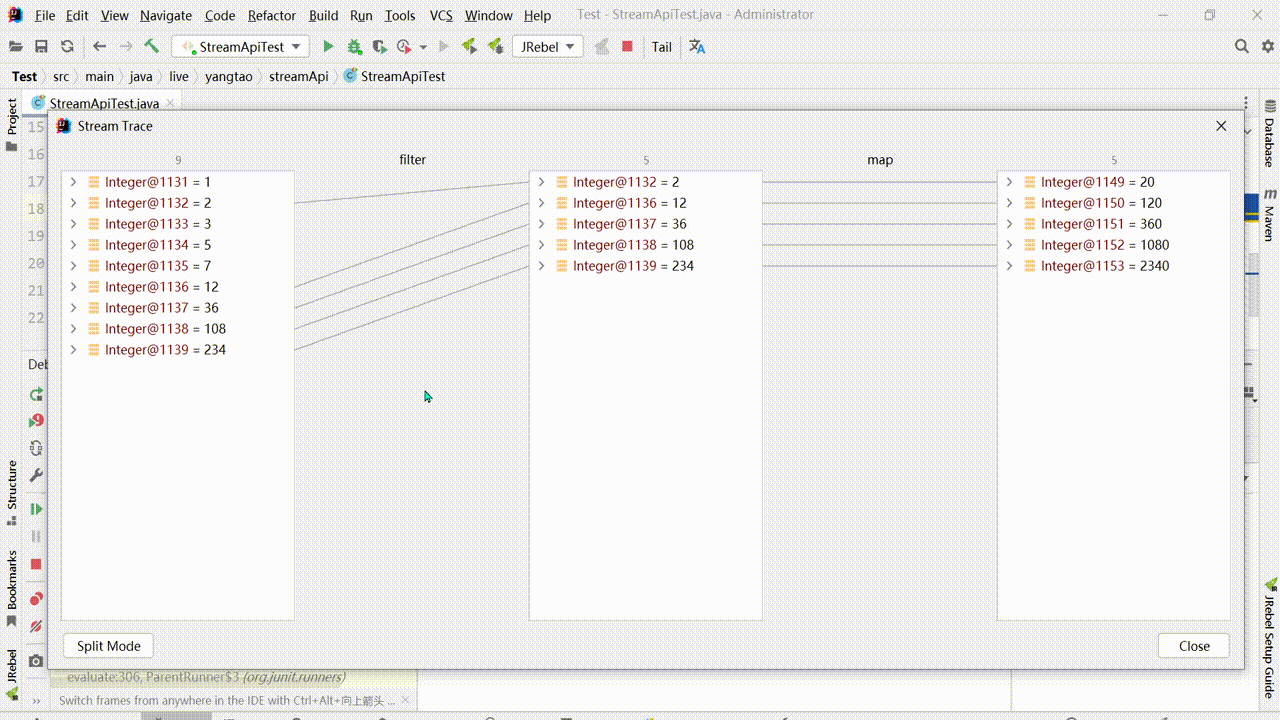
流式编程DEBUG,在添加断点的时候可以单独为一个中间操作加上断点,也可以加上行断点,对于整个中间操作过程可以通过Trace Current Stream Chain查看
附[1]:
Person类
1 | |
测试列表List<Person>
1 | |
最后
StreamAPI是现代Java编程中不可或缺的一部分,它使得数据的批量处理更加直观和简洁。通过链式调用,开发者可以编写出既简洁又强大的数据处理逻辑。然而,Stream的滥用或不当使用也可能导致性能下降,因此理解其内部机制和适当使用是至关重要的。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!