Redis——分布式锁
本文最后更新于:1 年前
引言
在分布式系统中,管理并发访问共享资源是一个挑战,需要确保系统的一致性和可靠性。分布式锁提供了一种机制,通过锁定资源来控制跨多个节点的并发访问。Redis,作为高性能的NoSQL数据库,由于其内存操作的特性和灵活的数据结构,被广泛用于实现分布式锁。本文详细介绍了分布式锁的概念、设计原则、实现方式,以及如何利用Redis和Lua脚本来实现高效且安全的分布式锁。
分布式锁简介
分布式锁是一种在分布式系统中用于避免多个进程或服务同时访问共享资源的同步机制。它是一种在单体应用中常见的互斥锁(Mutex)的扩展,特别是在需要确保跨多个节点的数据一致性和顺序时。
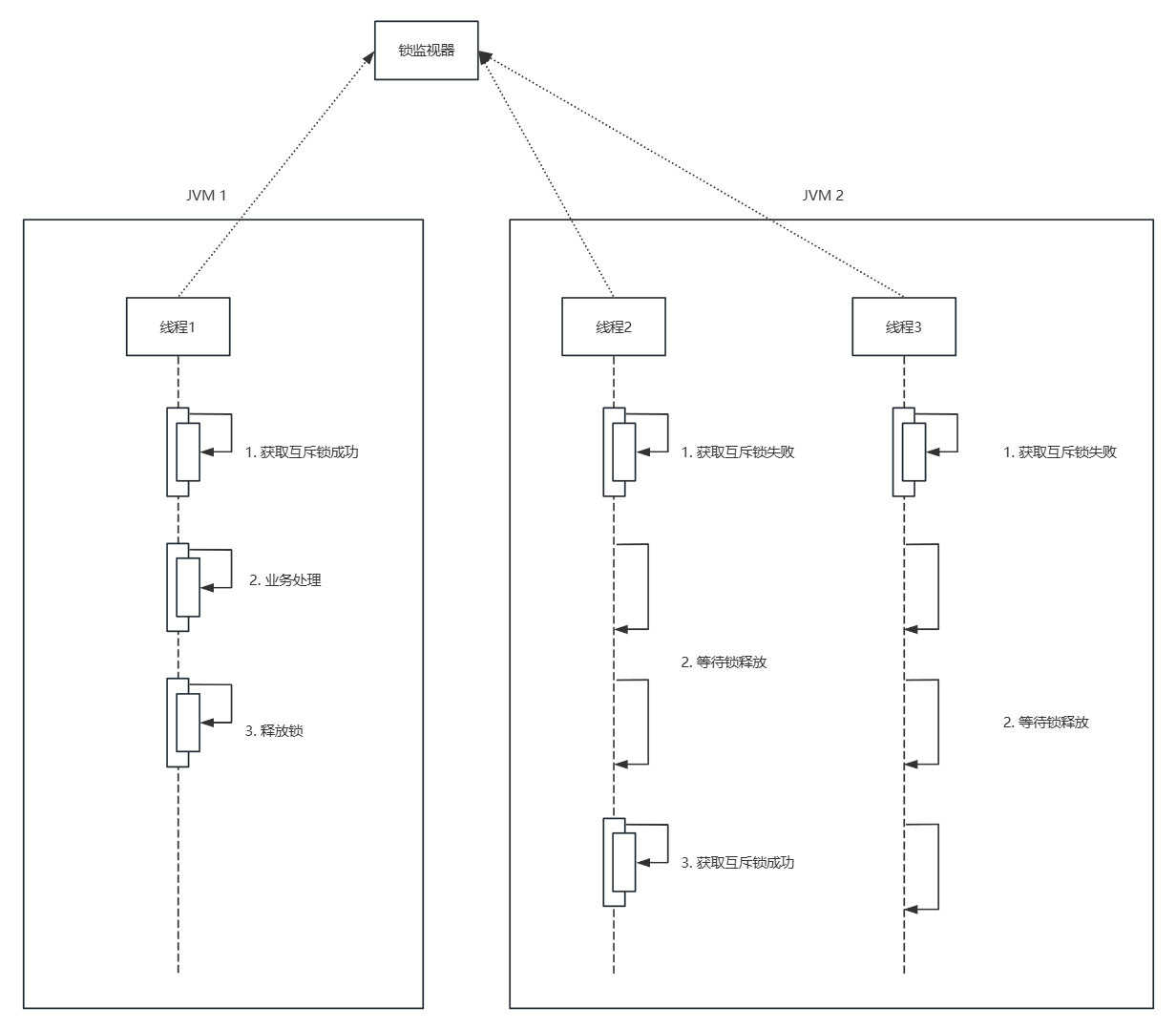
对比JVM锁
| JVM锁 | 分布式锁 | |
|---|---|---|
| **应用范围 ** | 单个JVM进程内部,如单个应用的多线程环境中 | 多个独立进程或服务,如微服务架构、集群应用和任何多个节点协作的场景 |
| 性能 | 单个进程内线程调度和内存访问,性能高、延迟低 | 受网络状况和锁实现机制的影响较大,网络延迟和外部服务处理速度为性能瓶颈 |
| 容错 | 处理单个JVM内的线程,JVM崩溃后锁自然消失,容错性通常没有问题 | 需要设计考虑节点故障、网络分区和其他分布式系统问题,确保锁的一致性和可恢复性 |
| 复杂性 | 相对简单,只需要理解Java多线程 | 设计和维护相对复杂,涉及到网络通信、错误处理、状态同步等分布式系统的问题 |
功能
- 互斥性:确保在同一时间内,只有一个进程或服务可以执行关键段(critical section)的代码或操作特定的资源。
- 避免死锁:通过合理设计和使用超时机制,分布式锁可以避免死锁情况的发生。
- 保持一致性:在分布式系统中,不同节点上的进程可能会试图同时修改同一个数据源,使用分布式锁可以保持数据操作的一致性。
应用场景
- 电子商务系统中的库存管理:在高并发环境下,多个用户可能同时尝试购买限量的商品。分布式锁可以确保在处理订单和减库存操作时的数据一致性。
- 支付系统:在处理支付操作时,分布式锁可以保证同一账户的支付操作不会同时进行,避免余额出现错误。
- 任务调度:在分布式任务调度系统中,分布式锁用来保证同一任务不会被多个调度实例同时执行。
- 数据聚合:在一个大数据平台中,多个进程可能需要对同一数据集进行处理和更新,使用分布式锁可以防止数据在更新时发生冲突。
设计原则
- 互斥性:在任何时刻,只有一个客户端可以持有锁。这是实现并发控制的基本要求,确保共享资源不会被多个进程同时修改,从而避免数据不一致。
- 死锁防范:需要考虑到死锁的可能性并提供解决方案。这通常通过引入锁超时机制来实现,这样可以防止因为某个持锁进程的故障导致资源被无限期锁定。
- 高可用:必须高度可用,任何不可用都可能导致依赖它的应用发生阻塞或失败。通常通过冗余部署(如使用主从复制或多节点集群)来增强锁服务的可用性。
- 容错性:分布式锁应该能够处理节点故障。如果一个持有锁的节点突然崩溃或网络分区,锁服务需要能够检测到这种情况并将锁释放,以免影响系统的整体功能。
- 高性能:锁的获取和释放操作应尽可能高效。设计时需要优化网络交互,减少锁操作的延迟,例如通过减少请求的往返次数、使用更快的序列化机制等
- 重入性:同一个线程可能需要多次获取同一把锁(递归锁定)。分布式锁的设计可考虑支持重入性,使得同一个节点或线程可以安全地多次申请同一资源。
- 公平性:设计分布式锁时可以考虑锁的公平性,即确保按照请求锁的顺序来分配锁。这可以防止某些节点因长时间得不到锁而产生的“饥饿”问题。
- 可伸缩性:随着系统规模的扩大,分布式锁的实现也应能够扩展以处理更高的并发请求,这可能意味着在多个锁服务节点之间有效分配请求,或是合理的资源分区策略。
- 安全性:尤其在公开或不完全受信的环境中,分布式锁的通信应该加密,防止恶意攻击如重放攻击或锁篡改。
实现方式
关系型数据库
优点:
强一致性:可以通过数据库事务保证操作的原子性和一致性。
熟悉度高:许多开发者对SQL和关系数据库非常熟悉,容易实现和维护。
缺点:
性能限制:数据库锁可能在高并发场景下性能较低,因为锁操作需要磁盘I/O,且通常涉及网络延迟。
可扩展性问题:随着请求量的增加,扩展关系数据库通常比较困难和昂贵。
NoSQL数据库
- 优点:
- 高性能:基于内存操作,响应速度快,适合高并发环境。
- 自然的超时机制:Redis键值可以设置过期时间,自然支持锁的超时释放。
- 高可用和扩展性:通过哨兵模式和集群模式,Redis可以提供高可用性和水平扩展。
- 缺点:
- 数据持久性问题:虽然Redis有持久化机制,但在极端情况下仍可能丢失数据。
- 锁不是自然的可重入:需要在客户端实现可重入逻辑。
Zookeeper
- 优点:
- 设计用于协调:ZooKeeper提供原生支持的分布式锁和其他同步原语,非常适合做分布式协调任务。
- 强一致性:ZooKeeper保证跨集群的数据一致性和顺序性。
- 容错性高:通过集群模式运行,能够处理节点失败的情况。
- 缺点:
- 复杂性高:比起Redis和MySQL,ZooKeeper的部署和维护更为复杂。
- 性能较低:由于强一致性的保证,性能可能不如基于内存的Redis。
三者对比
在选择分布式锁的实现技术时,需要考虑锁的性能需求、一致性要求、系统的可用性和容错性。MySQL提供了强一致性但可能在高并发下表现不佳;Redis提供了极高的性能和良好的扩展性,适合需要快速响应的场景;ZooKeeper提供了专门的协调服务,适合需要严格一致性和顺序保证的场景。每种技术都有其适用的场景和局限性,正确的选择应基于具体的应用需求和环境特点。
基本思路
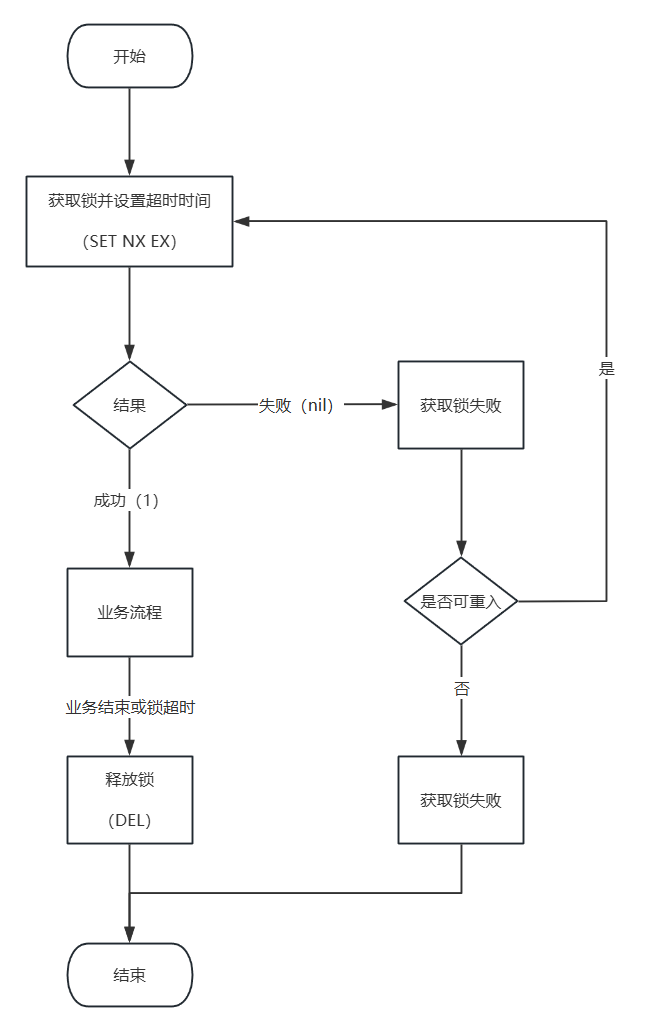
基于Redis实现分布式锁主要有两点:
获取锁
互斥:确保只有一个线程获取锁
1
SETNX lock threadId添加超时时间,避免死锁
1
EXPIRED lock 10注意获取锁和添加超时时间这两步必须是一个原子操作,避免设置超时时间前服务器宕机引发死锁问题,因此可以将两步合并为:
1
SET lock threadId EX 10 NX释放锁
手动释放
1
DEL lock
实现
根据以上实现思路编写Java程序如下:
创建接口RedisLock,接口包含获取锁以及解锁的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public interface RedisLock {
/**
* 尝试获取锁
*
* @param timeout 超时时间
* @return boolean 是否获取到锁
*/
boolean tryLock(long timeout);
/**
* 释放锁
*/
void unlock();
}创建该接口的一个实现类SimpleRedisLock
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36@Data
@NoArgsConstructor
@AllArgsConstructor
public class SimpleRedisLock implements RedisLock {
private static final String KEY_PREFIX = "REDIS_LOCK_";
// 类的成员变量,用于存储锁的key
private String key;
// 用于操作redis的组件
private StringRedisTemplate stringRedisTemplate;
/**
* 尝试获取锁
* 1. 获取当前线程的id
* 2. 尝试将当前线程的id存入redis,并设置过期时间
*
* @param timeout 超时时间
* @return boolean 是否获取到锁
*/
@Override
public boolean tryLock(long timeout) {
long threadId = Thread.currentThread().getId();
return Boolean.TRUE.equals(stringRedisTemplate.opsForValue()
.setIfAbsent(KEY_PREFIX +key, String.valueOf(threadId), timeout, TimeUnit.MILLISECONDS));
}
/**
* 释放锁:删除redis中的key
*/
@Override
public void unlock() {
stringRedisTemplate.delete(KEY_PREFIX + key);
}
}业务:用户同一时间多次下单的场景,使用互斥锁保证只有一个请求成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32@Service
public class OrderServiceImpl implements OrderService {
@Resource
private StringRedisTemplate stringRedisTemplate;
@Override
public String createOrder() {
SimpleRedisLock simpleRedisLock = new SimpleRedisLock("createOrder" + getUserId(), stringRedisTemplate);
boolean locked = simpleRedisLock.tryLock(20000);
// 如果获取锁失败,直接返回
if (!locked) {
return "获取锁失败";
}
// 获取锁成功,模拟创建订单
try {
return "创建订单成功";
} catch (Exception e) {
e.printStackTrace();
return "创建订单失败";
} finally {
// 创建订单结束后,释放锁
simpleRedisLock.unlock();
}
}
public String getUserId() {
// 模拟获取用户id
return "1";
}
}运行两个应用实例,用两次HTTP请求模拟同一时间多次下单,请求结果如下
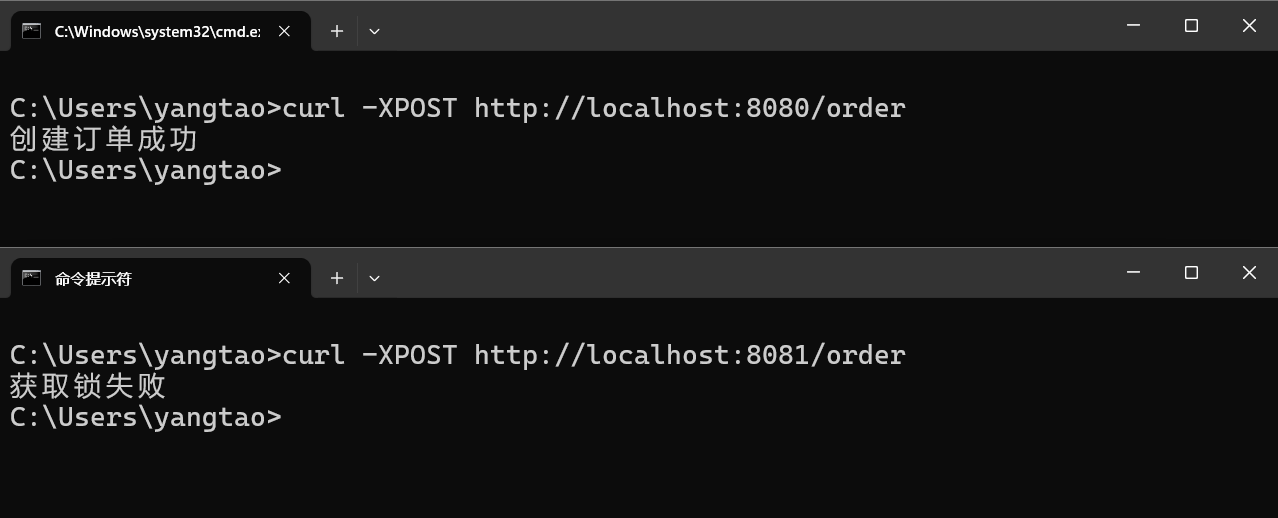
查看Redis数据库
1
2
3
4
5
6127.0.0.1:6379> keys *
1) "REDIS_LOCK_createOrder1"
127.0.0.1:6379> get REDIS_LOCK_createOrder1
"38"
127.0.0.1:6379> ttl REDIS_LOCK_createOrder1
(integer) 7由以上结果可知,OrderServiceImpl#createOrder已满足我们的业务需求,做到了用户同一时间只能下单一次,且从Redis数据库的查询结果也看出了SimpleRedisLock的工具类是按照我们上节提到的思路进行实现的。
改进一
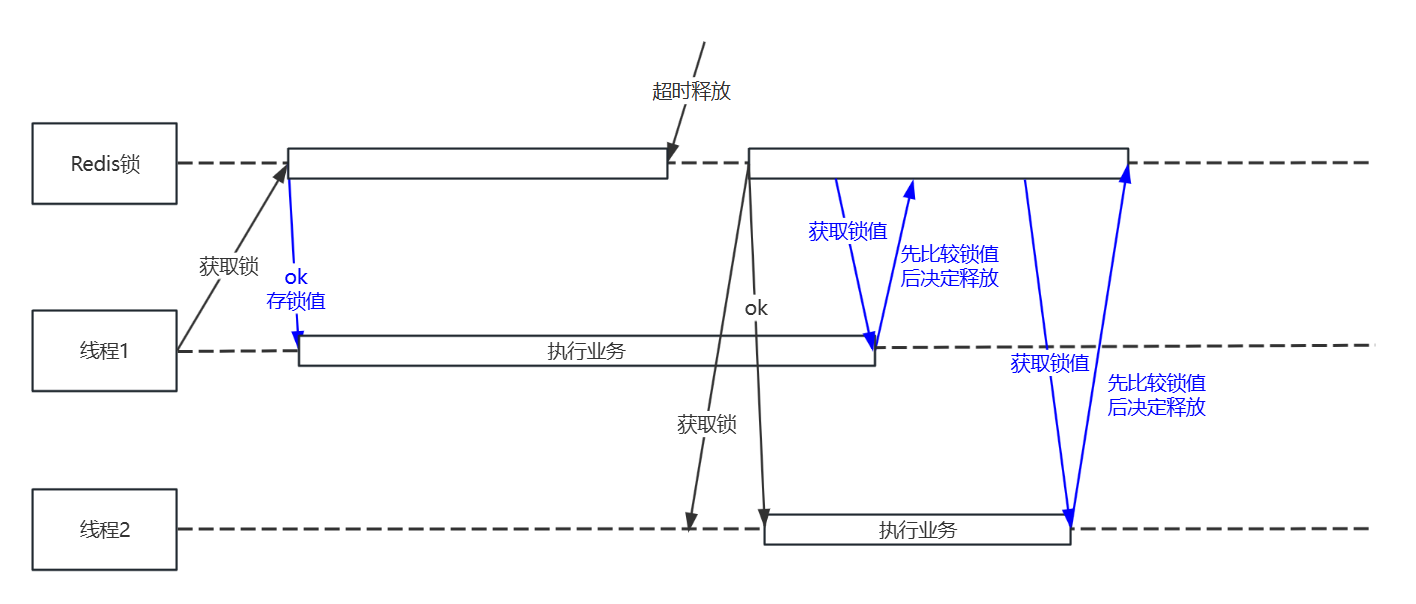
以上SimpleRedisLock看似已经满足了需求,但在某些极端条件下仍然会出错,如下图所示:
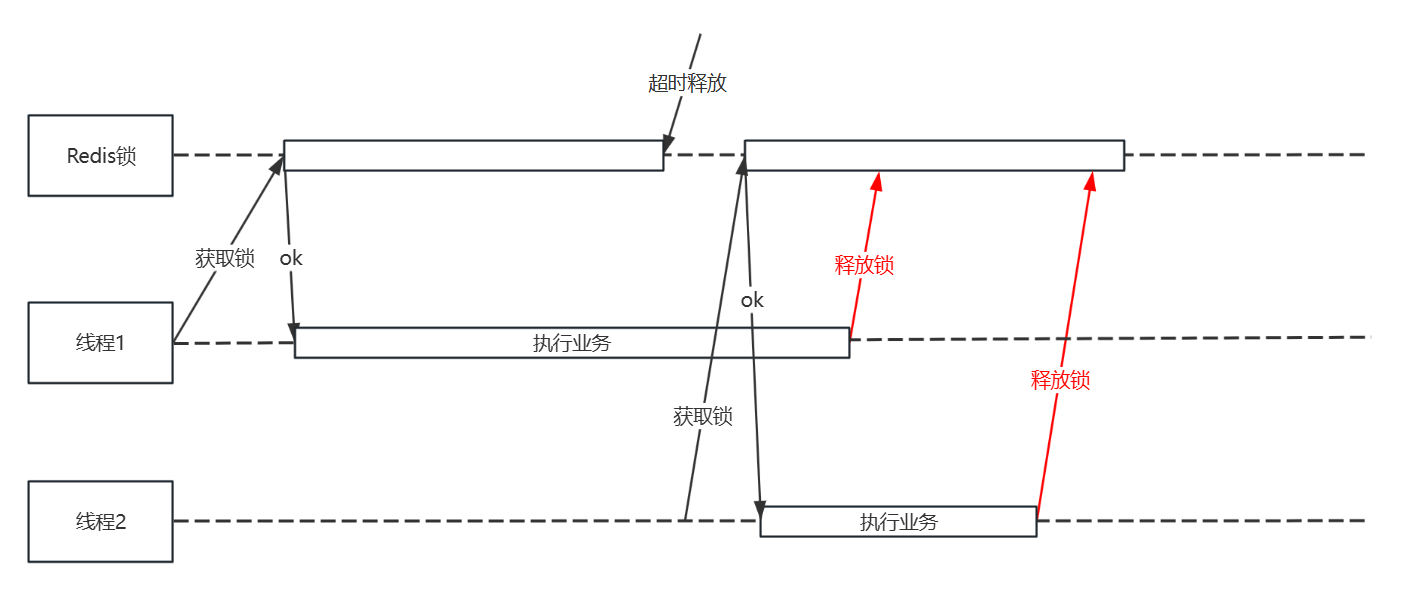
当线程1执行业务期间,锁超时释放,与此同时线程2获取到了相同key的锁,且在线程2的执行期间,线程1执行完成,对锁进行了释放,那么就会出现问题,线程1解锁了不属于自己的锁。
其实解决这个问题很简单,只需要对锁的值进行标记,在释放锁时对锁的值和本线程持有的值进行比较,相同才能解锁,即可解决这个“跨线程解锁”的问题。
修改SimpleRedisLock如下
1 | |
修改的核心逻辑为:添加成员变量LOCK_VALUE(取值为UUID),拿到互斥锁时需要将该值设置为Redis KEY的VALUE,分布式锁解锁时需要拿出Redis中对应分布式锁的VALUE值,与持有者的LOCK_VALUE进行比较,值相等时才能进行解锁,否则抛出异常(业务代码需要做对应处理)。
修复后,分布式锁的流程如下:
改进二
刚才我们解决了锁超时释放后、前一个线程解锁当前正在运行的线程的锁的问题。
现在还有一个极端情况:解锁逻辑中,线程A判断完Redis中锁的VALUE值与持有者的LOCK_VALUE值相等后,本来可以解锁,但是系统突然阻塞了(FULL GC)且阻塞时间极长,分布式锁都超时释放了,此时又有另一个线程B拿到了相同KEY的锁,且在执行业务期间,线程A停止阻塞解锁了分布式锁,如下图所示:
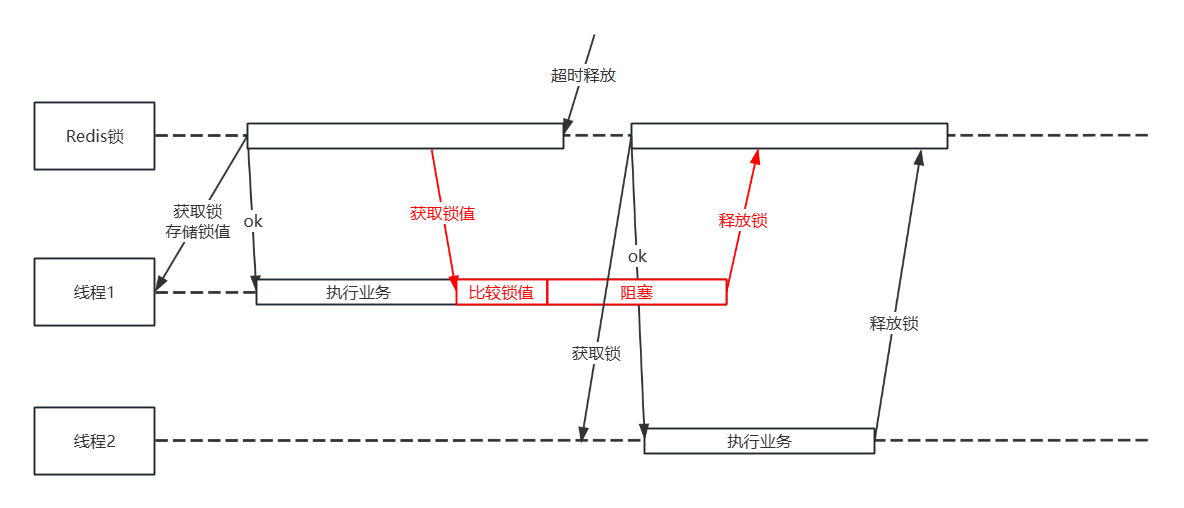
不难看出,这个问题的根因是比较持有者与Redis的锁值、释放锁这两步动作不是一个原子操作。因此下一步我们要实现的是解锁逻辑中的原子操作。
调用Lua脚本
Redis提供了执行Lua脚本的功能,这是一种强大的机制,用于处理多个操作需要在单个原子事务中执行的情况。
为什么使用Lua脚本
- 原子性:Lua脚本在执行时不会被其他命令中断,确保了脚本中所有操作的原子性。这是因为Redis是单线程的,一旦开始执行脚本,就会执行到结束,中间不会插入其他操作。
- 减少网络开销:通过将多个命令封装在一个脚本中发送,可以减少客户端与服务器之间的通信次数。这对于网络延迟敏感的应用尤其重要。
- 复杂逻辑处理:Lua脚本提供了比简单的Redis命令更复杂的逻辑处理能力,允许进行条件判断、循环处理等。
使用场景
- 复杂的事务:需要执行多个操作,这些操作要么全部完成,要么全部不做。
- 性能优化:减少多次网络往返带来的延迟。
- 安全性:例如,在分布式锁的实现中,确保只有锁的持有者才能释放锁。
分布式锁整合
以下是一个使用Lua脚本来安全释放Redis锁的例子。这个脚本检查锁是否由调用者持有,如果是,则释放锁:
1 | |
KEYS[1]表示锁KEY的名称。ARGV[1]表示调用者认为的锁的值。- 如果锁的当前值与提供的值匹配,则删除该键(释放锁),否则不执行任何操作。
同时改进SimpleRedisLock的解锁逻辑:
1 | |
以上代码中,修改了在Java程序中取值判断,将取值、判断、删除都整合到Lua脚本中,实现了三步操作的原子性。
总结
文章通过对分布式锁的全面介绍和深入的技术分析,提供了实现高效和安全分布式锁的详细方法。特别是通过Redis和Lua脚本实现的锁,不仅保证了操作的原子性,还解决了如锁超时和异常解锁的常见问题。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!