引言
在现代分布式系统中,消息队列起着至关重要的作用。它通过异步通信的方式,实现系统各服务间的解耦和流量削峰。对于初级场景,我们可能在单个 Java 应用中借助阻塞队列来简化异步处理,但随着业务需求的增长和系统架构的演进,跨进程通信、数据持久化、高并发以及分布式部署成为关键要素。此时,Redis 作为一款高性能的内存数据库,提供了多种消息队列实现方式——包括 List、Pub/Sub 和 Streams,从而在不同层次的需求下灵活应对。本篇文章将从一个简单的“订单保存”案例入手,循序渐进地介绍如何使用 Redis 取代单机内存队列,实现跨进程、多节点的异步处理,并探讨不同模式的优缺点、适用场景以及注意事项。
问题场景
订单保存订单操作
同步操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| @Override
@Transactional
public String saveIt(SalesOrder salesOrder) {
check(salesOrder);
String soNo = generateSoNo();
doSave(soNo);
return soNo;
}
public void doSave(String soNo) {
SalesOrder salesOrder = new SalesOrder();
salesOrder.setId(IdWorker.getId());
salesOrder.setSoNo(soNo);
save(salesOrder);
}
|
Java 内存异步
对于保存这个比较耗费时间的动作,可使用阻塞队列异步进行处理(基于内存)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
private static final BlockingQueue<String> QUEUE = new ArrayBlockingQueue<>(100000);
private static final ExecutorService EXECUTOR = Executors.newSingleThreadExecutor();
@Override
@Transactional
public String saveIt(SalesOrder salesOrder) {
check(salesOrder);
String soNo = generateSoNo();
asyncSave(soNo);
return soNo;
}
public void doSave(String soNo) {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
SalesOrder salesOrder = new SalesOrder();
salesOrder.setId(IdWorker.getId());
salesOrder.setSoNo(soNo);
save(salesOrder);
}
@PostConstruct
public void init() {
EXECUTOR.submit(new SaveTask());
}
public class SaveTask implements Runnable {
@Override
public void run() {
while (true) {
try {
doSave(QUEUE.take());
} catch (InterruptedException e) {
log.error("保存销售订单异常", e);
}
}
}
}
public void asyncSave(String soNo) {
QUEUE.add(soNo);
}
@PreDestroy
public void destroy() {
EXECUTOR.shutdown();
}
|
存在问题
- 不支持跨进程:异步数据不支持跨进程,仅限于同一个 JVM 进程内部。
- 无持久化实现:一旦应用退出或 JVM 崩溃,队列中的数据会丢失。
- 无分布式支持:Java 阻塞队列仅限于单个进程或节点使用,不适合分布式场景。
- 数据监控困难:Java 阻塞队列无法直接提供可观测性,需额外编写代码实现状态监控。
概述
消息队列是一种用于在不同系统组件之间传递数据的通信机制。它通过将消息存储在队列中,使得生产者和消费者可以异步地进行数据交换。Redis 作为一个内存数据库,凭借其高速读写能力和丰富的数据结构,常被用来实现高效的消息队列系统。
优点
- 高性能:Redis 基于内存,读写速度极快,能够处理大量的消息。
- 简单易用:通过简单的命令和数据结构即可实现基本的消息队列功能。
- 丰富的数据结构:支持多种数据结构(如
List、Pub/Sub、Streams),满足不同的应用场景。
- 持久化支持:通过
RDB 和 AOF 机制,Redis 能够持久化存储消息,防止数据丢失。
- 可扩展性:支持主从复制和分片,能够扩展到大型分布式系统。
- 跨进程:Redis 是基于网络的内存存储,支持多个进程或多种语言的客户端通过网络共享队列。
不足
- 内存消耗:Redis 基于内存存储,消息量大时会消耗大量内存,成本较高。
- 缺乏高级特性:相比于专门的消息队列系统(如
RabbitMQ、Kafka),Redis 在消息路由、事务支持等方面功能有限。
- 消息持久化性能:虽然 Redis 支持持久化,但在高并发下,持久化性能可能成为瓶颈。
- 可靠性:在某些实现方式中(如
List 和 Pub/Sub),缺乏完善的消息确认和重试机制,可能导致消息丢失或重复消费。
List消息队列
概述
Redis List 是一个列表数据结构,支持从队列的头部或尾部插入和移除元素,非常适合用来实现队列。
基本原理

在使用 Redis 实现消息队列时,通常将一个 Redis List 作为队列:
- 生产者(Producer):将消息插入队列的一个端(通常是左端)。
- 消费者(Consumer):从队列的另一个端弹出消息(通常是右端),以实现先进先出(
FIFO)的队列行为。
这种模式利用了 Redis List 的高效插入和弹出操作,适用于简单的消息传递需求。
优缺点
优点:
简单易用:只需使用 LPUSH 和 BRPOP 等简单命令即可实现消息队列。。
高性能:Redis 基于内存,读写速度极快,适合高吞吐量的消息传递。
阻塞操作:BRPOP 命令支持阻塞弹出,消费者可以高效地等待新消息,减少轮询开销。
持久化支持:通过 Redis 的持久化机制,可以在一定程度上保证消息的持久性。
缺点:
- 缺乏消息确认机制:使用
Redis List 实现的队列没有内置的消息确认机制,可能导致消息丢失或重复消费。
- 无法实现消费者组:无法像
Redis Streams 那样支持多个消费者组,难以实现消息的负载均衡和广播。
- 有限的功能:相较于
Redis Streams 或专门的消息队列系统,List实现的消息队列功能较为基础,缺乏高级特性如消息重试、消息优先级等。
- 内存消耗:所有消息存储在内存中,消息量大时会占用大量内存资源。
适用场景
- 简单的任务队列:适用于异步处理任务,如发送邮件、图片处理等。
- 轻量级消息传递:适用于不需要复杂消息确认和消费者管理的场景。
- 实时通知:适用于低延迟的通知系统,虽然不如
Pub/Sub 实时,但在队列模式下具备一定的灵活性。
- 短期存储和处理:适用于消息量较小且不需要长期存储的场景。
Redis命令示例
|
127.0.0.1:6379> LPUSH myqueue "message1"
(integer) 1
127.0.0.1:6379> LPUSH myqueue "message2"
(integer) 2
127.0.0.1:6379> BRPOP myqueue 0
1) "myqueue"
2) "message1"
|
- myqueue:队列名称
- 0:阻塞时间,单位为秒,0表示无限等待。
代码示例
使用 RedisTemplate 操作 Redis List,往保存订单的队列中添加消息,同时启用消费者线程将队列中的消息取出进行消费(创建订单)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
| @Resource
private RedisTemplate<String, String> redisTemplate;
private static final ExecutorService EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
public void init() {
EXECUTOR.submit(new OrderSaveListConsumer(redisTemplate));
}
@Override
@Transactional
public String saveIt(SalesOrder salesOrder) {
check(salesOrder);
String soNo = generateSoNo();
asyncSave(soNo);
return soNo;
}
public void asyncSave(String soNo) {
redisTemplate.opsForList().leftPush(OrderSaveListConsumer.ASYNC_SAVE_QUEUE, soNo);
}
@AllArgsConstructor
private static class OrderSaveListConsumer implements Runnable {
public static final String ASYNC_SAVE_QUEUE = "order.save.queue";
private final RedisTemplate<String, String> redisTemplate;
@Override
public void run() {
while (true) {
try {
String message = redisTemplate.opsForList().rightPop(ASYNC_SAVE_QUEUE);
if (StrUtil.isNotBlank(message)) {
SpringUtil.getBean(SalesOrderServiceImpl.class).doSave(message);
}
} catch (Exception e) {
log.error("处理销售订单异常", e);
}
}
}
}
public void doSave(String soNo) {
SalesOrder salesOrder = new SalesOrder();
salesOrder.setId(IdWorker.getId());
salesOrder.setSoNo(soNo);
save(salesOrder);
}
@PreDestroy
public void destroy() {
EXECUTOR.shutdown();
}
|
使用 Redisson 也可以完成相同的操作,只需对上面生产和消费的方法进行简单的改造。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
| @Resource
private RedisTemplate<String, String> redisTemplate;
private static final ExecutorService EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
public void init() {
EXECUTOR.submit(new OrderSaveListConsumer(redissonClient));
}
@Override
@Transactional
public String saveIt(SalesOrder salesOrder) {
check(salesOrder);
String soNo = generateSoNo();
asyncSave(soNo);
return soNo;
}
public void asyncSave(String soNo) {
redissonClient.getQueue(OrderSaveListConsumer.ASYNC_SAVE_QUEUE).add(soNo);
}
@AllArgsConstructor
private static class OrderSaveListConsumer implements Runnable {
public static final String ASYNC_SAVE_QUEUE = "order.save.queue";
private final RedissonClient redissonClient;
@Override
public void run() {
while (true) {
try {
List<Object> poll = redissonClient.getQueue(ASYNC_SAVE_QUEUE).poll(1);
if (CollUtil.isEmpty(poll)) {
continue;
}
Object o = poll.get(0);
if (o == null || StrUtil.isBlank(o.toString())) {
continue;
}
SpringUtil.getBean(SalesOrderServiceImpl.class).doSave(o.toString());
} catch (Exception e) {
log.error("处理销售订单异常", e);
}
}
}
}
public void doSave(String soNo) {
SalesOrder salesOrder = new SalesOrder();
salesOrder.setId(IdWorker.getId());
salesOrder.setSoNo(soNo);
save(salesOrder);
}
@PreDestroy
public void destroy() {
EXECUTOR.shutdown();
}
|
使用 Redis List 实现消息队列适用于简单、低复杂度的场景,如基本的任务异步处理和轻量级消息传递。然而,由于其缺乏高级特性和在可靠性、扩展性方面的局限,当业务需求变得复杂或对消息队列的可靠性要求更高时,可能需要考虑其他解决方案。
Pub/Sub消息队列
概述
Redis 的 Pub/Sub(发布/订阅)是一种消息传递模式,允许消息生产者(发布者)向一个或多个频道发布消息,而消息消费者(订阅者)订阅这些频道以接收相关消息。Pub/Sub 模式适用于实时消息传递和广播场景。
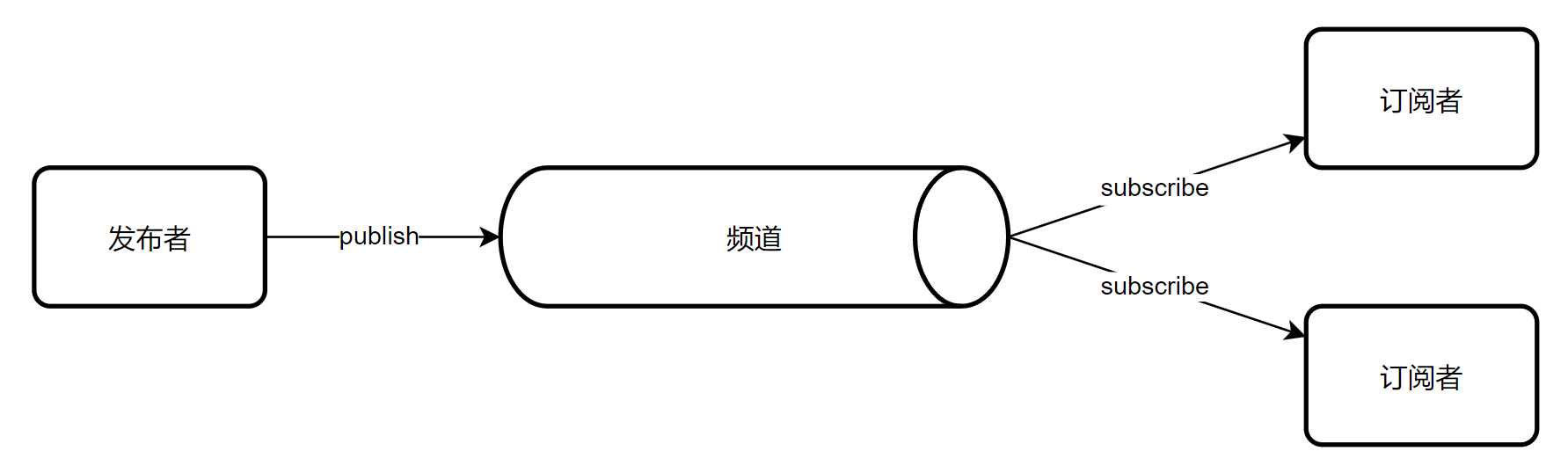
Redis 通过维护频道与订阅者的映射关系,实现消息的即时推送。发布者和订阅者之间无需直接通信,Redis 负责将消息分发给所有订阅者。
优缺点
优点:
- 实时性强:消息一旦发布,所有订阅者立即接收到,无需轮询或等待。
- 简单易用:通过简单的
PUBLISH 和 SUBSCRIBE 命令即可实现消息传递。
- 广播机制:支持将消息广播给所有订阅者,适合实时通知和广播场景。
- 低延迟:基于内存操作,消息传递延迟极低。
缺点:
- 无持久化:消息不会被持久化,订阅者必须在线才能接收消息,离线订阅者将错过消息且后续也无法获取。
- 无消息确认机制:发布的消息无法确认是否被订阅者成功接收,存在消息丢失的风险。
- 不支持消费者组:无法像
Streams 那样实现负载均衡和消息分发给多个消费者组。
- 只有广播模式:
Pub/Sub 本质上是广播机制,每个订阅者都会收到发布频道的消息,因此如果一个服务有多个实例的话会被多次消费,应该注意业务逻辑的正确性。
适用场景
- 实时通知系统:如在线聊天、即时消息推送、实时监控报警等,需要实时将消息推送给多个用户。
- 事件驱动架构:微服务之间的事件通知和实时通信,确保各服务能够即时响应事件。
- 直播和广播:适用于需要将数据实时广播给多个订阅者的场景,如直播平台的数据分发。
- 即时数据更新:如实时股票行情、体育比赛得分更新等,确保客户端能够即时接收最新数据。
Redis命令示例
|
127.0.0.1:6379> SUBSCRIBE mychannel
1) "subscribe"
2) "mychannel"
3) (integer) 1
127.0.0.1:6379> PUBLISH mychannel "Hello, Subscribers!"
(integer) 2
1) "message"
2) "mychannel"
3) "Hello, Subscribers!"
|
代码示例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| @Resource
private RedisTemplate<String, String> redisTemplate;
@Resource
private RedissonClient redissonClient;
public void asyncSave(String soNo) {
redisTemplate.convertAndSend(OrderSaveSubscriber.ASYNC_SAVE_CHANNEL, soNo);
redissonClient.getTopic(OrderSaveSubscriber.ASYNC_SAVE_CHANNEL).publish(soNo);
}
@Component
private static class OrderSaveSubscriber {
private static final String ASYNC_SAVE_CHANNEL = "order.save.channel";
@Bean
public RedisMessageListenerContainer container(RedisConnectionFactory connectionFactory,
MessageListener listener) {
RedisMessageListenerContainer container = new RedisMessageListenerContainer();
container.setConnectionFactory(connectionFactory);
container.addMessageListener(listener, new ChannelTopic(ASYNC_SAVE_CHANNEL));
return container;
}
@Bean
public MessageListener listener() {
return (message, pattern) -> {
String soNo = new String(message.getBody());
log.info("接收到销售订单号:{}", soNo);
SpringUtil.getBean(SalesOrderServiceImpl.class).doSave(soNo);
};
}
}
|
注意:Pub/Sub 为广播模式,请特别注意多个实例导致的重复消费问题。
虽然 Pub/Sub 模式在即时消息传递和广播通知方面表现出色,但它缺乏消息持久化和确认机制,导致在某些情况下可能会出现消息丢失或重复消费的问题,为此 Redis 5.0 中引入了 Streams 数据结构,提供了更加丰富和可靠的消息队列功能。
Stream消息队列
概述
Redis Streams 是 Redis 5.0 引入的一种新的数据结构,旨在提供更强大和灵活的消息队列功能。与 Redis List 和 Pub/Sub 不同,Redis Streams 支持消息的持久化、消费者组、消息确认和重试机制,使其适用于需要高可靠性和复杂消息处理逻辑的场景。
基本原理
在 Redis Streams 中,消息以条目的形式存储在一个有序的日志中。每个条目都有一个唯一的 ID(通常是时间戳加序列号),并包含一个或多个字段-值对。生产者将消息添加到流中,而消费者则通过消费者组读取和处理这些消息。
核心概念:
- Stream(流):消息的集合,类似于一个日志。
- Entry(条目):流中的单条消息,包含唯一
ID 和字段-值对。
- Consumer Group(消费者组):一组消费者共同消费流中的消息,每条消息只被组内一个消费者处理。
- Pending Entries(待处理条目):消费者组中尚未被确认的消息。
- Acknowledge(确认):消费者确认已成功处理某条消息。
通过这些机制,Redis Streams 实现了高可靠性、负载均衡和消息持久化。
优缺点
优点:
- 持久化:消息被持久化存储,确保在 Redis 重启后消息不会丢失。
- 消费者组:支持多个消费者组,每个组独立消费消息,实现负载均衡。
- 消息确认:消费者可以确认已处理的消息,支持消息的重试机制,确保消息不丢失。
- 消息ID:每条消息有唯一的
ID,支持按时间范围或特定 ID 查询消息。
- 回溯和历史查询:支持消费组可以从任意位置开始消费,甚至回溯历史消息。
缺点:
- 使用复杂度较高:相比
Redis List 和 Pub/Sub,Redis Streams 的概念和使用方式更为复杂,学习曲线较陡。
- 资源消耗:虽然 Redis 本身高效,但
Redis Streams 的持久化和消费者组机制可能会增加一定的资源消耗。
- 不适合实时广播:
Redis Streams 更适用于工作队列模式,而非实时广播场景。
适用场景
- 复杂的任务队列:需要消息确认和重试机制,确保任务不丢失。需要负载均衡,多个消费者组共同处理任务。
- 事件驱动架构:微服务之间的事件传递,确保每个事件被至少一个服务处理。
- 日志收集和处理:实时收集和处理大量日志数据,确保数据不丢失。
- 实时数据处理:需要处理实时数据流,如实时分析、监控等。
- 金融交易系统:需要高可靠性和顺序保证的交易消息处理。
单消费者
生产者往指定的流中推送消息,消费者则可以从流中读取消息。
XADD
|
XADD key [NOMKSTREAM] [MAXLEN|MINID [=|~] threshold [LIMIT count]] *|id field value [field value ...]
XADD mystream * field1 value1 field2 value2
XADD mystream MAXLEN ~ 1000 * field1 value1
XADD mystream MINID ~ 1680000000000-0 * field1 value1
|
- key:流的名称。
- NOMKSTREAM:如果流不存在,不自动创建;默认是自动创建流。
- MAXLEN|MINID:控制流的长度。
- MAXLEN:通过指定消息数量限制流的长度。
- MINID:按消息
ID 删除早于指定 ID 的消息。
- **=**:严格删除,确保不超过指定限制。
- **~**:近似删除(默认),性能更高但结果不精确。
- threshold:长度或
ID 的限制值。
- LIMIT count:限制每次删除的消息数量(与
MAXLEN|MINID 配合使用)。
- *****:由 Redis 自动生成消息
ID(时间戳 + 序列号)。
- id:用户自定义的消息
ID。
- field value:消息内容,由键值对组成。
XREAD
|
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
XREAD COUNT 10 STREAMS mystream 0
XREAD BLOCK 5000 STREAMS mystream $
|
COUNT count:一次读取的最大消息数量。
BLOCK milliseconds:阻塞等待的时间(毫秒),如果没有新消息立即返回,0 表示无限等待。
**STREAMS key [key …]**:指定要读取的 Redis Streams。
**id [id …]**:指定起始读取的消息 ID。
- 0:从第一个消息开始。
- **$**:从最新的消息开始。
Java 程序伪代码
|
while (true) {
Object msg = redis.execute("XREAD COUNT 1 BLOCK 2000 STREAMS mystream $")
if (msg != null) {
continue;
}
handleMessage(msg);
}
|
问题:如果在处理消息的过程中,生产者连发消息,那单消费者只处理最新的一条会导致漏处理消息。
消费者组
消费者组可以将多个消费者划分到同一个组中,监听同一个队列,可以实现:
- 消息分流:队列中的消息会被分流到组内不同消费者,而不重复消费,加快消息处理的速度。
- 消费标示:消费者组会维护一个标识,记录最后一个被处理的消息,每次消费都从未被处理的消息开始。
- 消费确认:消费者获取消息后,消息处于
Pending 状态,并存入一个 Pending Entries List。当处理完成后需要通过 XACK 确认消息,标记为已处理,从 Pending Entries List 中移除。
XGROUP
|
XGROUP CREATE key group id|$ [MKSTREAM] [ENTRIESREAD entries-read]
XGROUP CREATE mystream mygroup 0 MKSTREAM
XGROUP CREATE mystream mygroup $ MKSTREAM
|
|
XGROUP CREATECONSUMER key group consumer
XGROUP CREATECONSUMER mystream mygroup consumer1
|
- key:流的名称。
- group:消费者组名称。
- consumer:消费者名称。
|
XGROUP DELCONSUMER key group consumer
XGROUP DELCONSUMER mystream mygroup consumer1
|
- key:流的名称。
- group:消费者组名称。
- consumer:消费者名称。
|
XGROUP DESTROY key group
XGROUP DESTROY mystream mygroup
|
XREADGROUP
|
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] id [id ...]
XREADGROUP GROUP mygroup consumer1 COUNT 10 BLOCK 5000 STREAMS mystream >
XREADGROUP GROUP mygroup consumer1 STREAMS mystream 0
|
GROUP group consumer:指定消费者组和消费者名称。
COUNT count:一次读取的最大消息数量。
BLOCK milliseconds:阻塞等待时间(毫秒)。
NOACK:不等待确认,消息不会进入 Pending Entries List(PEL)。
**STREAMS key [key …]**:指定要读取的 Redis Streams。
**id [id …]**:
- **>**:从未被消费的消息开始读取。
- 其他 ID:从指定
ID 开始读取。
XACK
|
XACK key group id [id ...]
XACK mystream mygroup 1640345568000-0
|
- key:流的名称。
- group:消费者组的名称。
- id:要确认的消息
ID,可以同时指定多个。
XPENDING
|
XPENDING key group [[IDLE min-idle-time] start end count [consumer]]
|
- key:流的名称。
- group:消费者组的名称。
- IDLE min-idle-time:仅返回在 PEL 中等待超过指定时间(毫秒)的消息。
- start:查询起始的消息
ID,- 表示最早的消息。
- end:查询结束的消息
ID,+ 表示最新的消息。
- count:限制返回的消息数量。
- consumer:指定消费者,查询该消费者的待确认消息。
代码示例
使用 RedisTemplate 操作 Redis Streams,向指定流中添加消息,同时启用消费者线程将流中的消息取出进行消费(创建订单)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
| @Resource
private RedisTemplate<String, String> redisTemplate;
private static final ExecutorService EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
public void init() {
EXECUTOR.submit(new OrderSaveStreamConsumer(redisTemplate));
}
public void asyncSave(String soNo) {
redisTemplate.opsForStream().add("stream.orders", new HashMap<String, String>(1) {{
put("soNo", soNo);
}});
}
@AllArgsConstructor
private static class OrderSaveStreamConsumer implements Runnable {
private static final String STREAM_KEY = "stream.orders";
private static final String GROUP_NAME = "order.group";
private final RedisTemplate<String, String> redisTemplate;
@Override
public void run() {
if (!redisTemplate.hasKey(STREAM_KEY)) {
redisTemplate.opsForStream().createGroup(STREAM_KEY, GROUP_NAME);
}
while (true) {
try {
List<MapRecord<String, Object, Object>> list = redisTemplate.opsForStream().read(
Consumer.from(GROUP_NAME, "consumer-1"),
StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed())
);
if (CollUtil.isEmpty(list)) {
continue;
}
for (MapRecord<String, Object, Object> entries : list) {
String messageId = entries.getId().getValue();
entries.getValue().forEach((k, v) -> {
if ("soNo".equals(k.toString())) {
SpringUtil.getBean(SalesOrderServiceImpl.class).doSave(v.toString());
}
});
redisTemplate.opsForStream().acknowledge(STREAM_KEY, GROUP_NAME, messageId);
}
} catch (Exception e) {
log.error("处理销售订单异常", e);
}
}
}
}
@PreDestroy
public void destroy() {
EXECUTOR.shutdown();
}
|
可使用 Redisson 替代 RedisTemplate 操作 Redis Stream
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| @Resource
private RedissonClient redissonClient;
private static final ExecutorService EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
public void init() {
EXECUTOR.submit(new OrderSaveStreamConsumer(redissonClient));
}
public void asyncSave(String soNo) {
redissonClient.getStream("stream.orders").add("soNo", soNo);
}
@AllArgsConstructor
private static class OrderSaveStreamConsumer implements Runnable {
private static final String STREAM_KEY = "stream.orders";
private static final String GROUP_NAME = "order.group";
private final RedissonClient redissonClient;
@Override
public void run() {
RStream<Object, Object> initialStream = redissonClient.getStream(STREAM_KEY);
if (initialStream.size() == 0) {
initialStream.createGroup(GROUP_NAME);
}
while (true) {
try {
Map<StreamMessageId, Map<Object, Object>> streamMessageIdMapMap = initialStream.readGroup(GROUP_NAME, "consumer-1");
streamMessageIdMapMap.forEach((streamMessageId, map) -> {
map.forEach((k, v) -> {
if ("soNo".equals(k.toString())) {
SpringUtil.getBean(SalesOrderServiceImpl.class).doSave(v.toString());
}
});
initialStream.ack(GROUP_NAME, streamMessageId);
});
} catch (Exception e) {
log.error("处理销售订单异常", e);
}
}
}
}
@PreDestroy
public void destroy() {
EXECUTOR.shutdown();
}
|
对比其他MQ
| 特性 |
Redis (List/PubSub/Streams) |
RabbitMQ |
Kafka |
RocketMQ |
| 消息模型 |
List:工作队列;Pub/Sub:广播;Streams:可靠消息 & 消费者组 |
AMQP 协议,队列交换机模式,丰富路由规则 |
发布/订阅模型,分区+副本,多用于日志流处理 |
与 Kafka 类似,支持主题+分区 & 多种协议 |
| 消息持久化 |
Pub/Sub 无持久化;List/Streams 支持持久化 |
高度可配置,默认持久化 |
按日志存储,天然持久化且不可修改 |
同样按日志存储,支持多级存储 |
| 消息确认与重试 |
List 无确认;Pub/Sub 无确认;Streams 有确认 & 重试 |
拥有完备的 ACK & 重发机制 |
有 Consumer Group,手动提交偏移量 |
有 ACK,支持消息重试,支持死信队列 |
| 消费者组 & 负载均衡 |
Streams 支持消费者组;List、Pub/Sub 不支持 |
有队列绑定,多消费者可负载均衡 |
有 Consumer Group,自动负载均衡 |
Topic + Consumer Group, 负载均衡 |
| 消息路由功能 |
较简单(Streams 没有高级路由),List & Pub/Sub 几乎无路由功能 |
复杂路由规则(topic、direct、fanout 等) |
简单(按 topic + partition) |
相对灵活(Topic、Tag、Key 等),略低于 RabbitMQ |
| 吞吐量 & 性能 |
基于内存,单机性能较高,分布式扩展需要 Redis Cluster; |
轻量但单机吞吐量中等,集群方式提升吞吐量 |
高吞吐量,专为海量日志和流处理设计 |
与 Kafka 类似,吞吐量较高 |
| 应用场景 |
中小型异步处理、高速缓存消息、简易通知;Streams 可做可靠队列 |
需要灵活路由、强大队列功能和扩展性 |
大规模日志分析、流数据处理、事件驱动体系 |
与 Kafka 类似,国内金融、电商常用 |
| 学习成本 |
List/PubSub 简单;Streams 较复杂 |
较高(AMQP 概念相对丰富) |
较高(分区、副本、偏移量等概念) |
较高(类似 Kafka 但细节有所差异) |
选择建议:
- 如果仅需要简单异步和高性能,对消息的可靠性和复杂路由要求不高,可首选
Redis List 或 Pub/Sub。
- 如果需要消息持久化、确认、重试等较高可靠性保障,又希望借助 Redis 的高性能和易部署,可用
Redis Streams。
- 如果对消息路由、高可用集群、巨量日志处理等要求高,或需要复杂的消息模式(
RPC、事务消息、定时消息等),则可考虑 RabbitMQ / Kafka / RocketMQ 等专业消息队列系统。
总结
通过对 Java 内存队列和 Redis 不同消息队列实现(List、Pub/Sub、Redis Streams)的对比,可以发现 Redis 天然支持跨进程、可持久化且能在分布式环境下灵活扩展,适合在生产级别的高并发场景中使用。Redis List 适用于轻量、简单的异步处理;Pub/Sub 强调实时广播;而 Redis Streams 则在消息确认、消费者组和重试机制方面更进一步,适合对可靠性要求更高的复杂场景。
在实际项目中,如何选择合适的 Redis 消息队列方案,取决于对消息可靠性、吞吐量、延迟以及系统复杂度的综合考量。如果你需要更丰富的消息路由与高可靠性保证,也可以考虑专业的消息队列系统(RabbitMQ、Kafka、RocketMQ 等)。但对于中小型或对延迟要求较高的项目而言,Redis 依然是一个高效而简洁的解决方案。
由于篇幅原因,以下几个方向的内容今后再重新整理:
- 幂等性和重试:探索如何结合 Redis 的
XPENDING、XCLAIM 等命令实现安全可靠的消息重试。
- 高可用与可观测性:借助 Redis 集群、哨兵模式,以及监控工具(
Grafana + Prometheus)构建全面的可视化监控体系。
- 与其他消息队列对比:根据业务需求,从事务支持、消息路由、消费模式等角度对比
RabbitMQ、Kafka、RocketMQ 等系统的优劣点。